Kapitel 5 Softwareentwicklung
[Begriffsdefinition]Der Begriff Software umfasst alle Programme, Verfahren, zugehörige Dokumentationen und Daten, welche mit dem Betrieb eines Computersystems zu tun haben. Damit wird auch deutlich, dass Software weit mehr als “nur” Programme umfasst. Einerseits ist die Entwicklung, mit der Spezifikation, der Implementierung und dem Testen ein Teil des Begriffsverständnisses von Software. Andererseits darf auch nicht auf die Wartung, Anpassungen, Erweiterungen, Verbesserungen und Fehlerbehebungen verzichtet werden. Somit ist auch die Entwicklung ein wesentlicher Bestandteil von Software. Die Softwareentwicklung lässt sich wie folgt definieren: Die Softwareentwicklung umfasst alle Tätigkeiten und Ressourcen, welche zur Erstellung von Software notwendig sind. Dabei soll sie die Bedürfnisse der Kunden beziehungsweise Auftragsgeber in Software umsetzen (Lemberg 2011, 5–11).
[Hintergrund]Die Softwareentwicklung begann circa 1930 und wird durch zwei Aspekte geprägt. Einerseits gibt es einen enormen Fortschritt in der Entwicklung von Hardware. Daraus resultiert eine steigende Komplexität der Software, welche bereits den Weg in nahezu alle Haushaltsgeräte gefunden hat. Andererseits gibt es eine sehr lange Liste an Softwarefehlern, die nicht nur kostenintensiv waren, sondern leider auch Menschenleben gekostet haben. Beispiele für die Softwarefehler sind:
- Im Jahr 1993 wurde ein Pentium-Chip auf den Markt gebracht, welcher einen Berechnungsfehler bei der Division hatte. Die Division war ungenau, wirkte sich aber erst mehrere Stellen nach dem Komma aus. Dieser Fehler führte jedoch zu einem teuren Austausch der Prozessoren.
- Als eines der bekannten Beispiele der Raketenabstürze gilt sicher die Ariane 5 im Jahr 1996. Durch einen unsinnigen Befehl des Hauptrechners zerstörte sich die Rakete selbst. Das Problem entstand, da die Software vom Vorgängermodell übernommen wurde.
- 2007 ergaben sich bei einem Tabellenkalkulationsprogramm Fehler in Berechnungen, so ergab die Multiplikation \(10,2 \cdot 6425\) die Zahl \(100000\) statt \(65535\).
Seit 1960 wird die Softwareentwicklung immer mehr systematisiert, was zur ingenieur-wissenschaftlichen Disziplin des Software-Engineerings wurde (Kleuker 2009, 3–6).
5.1 Historische Entwicklung
[Monolithen]Trotz der nicht weit in die Vergangenheit reichenden Geschichte der Computer gab es einige Änderungen in deren Architektur und somit auch in der Software und Softwareentwicklung. Die Systeme bestanden bis in die 1970er aus einem zentralen Rechner, einem sogenannten Host und Terminals ohne allzu großer Intelligenz. In den 1980er wurden die Programme dann monolithisch entwickelt. Es befanden sich die GUI (general user interface), die Applikationslogik und die Datenhaltung in ein und derselben Einheit. Somit bestand die Software aus einem untrennbaren Gebilde, welches auf jedem Rechner installiert werden musste (Meyer 2018, 94).
[Client/Server]In den 1990ern wurde nicht mehr die Idee des monolithischen Programms vertreten, sondern die Client/Server-Systeme. Zunächst konzentrierte man sich auf Thin Clients (leichtgewichtige Clients) und teilte den Server in mehrere Schichten (Tiers) auf. Beispielsweise bekam die Datenbank, die Businesslogik und die GUI jeweils eine eigene Schicht. Die Server wurden komponentenbasiert umgesetzt, wobei diese Komponenten auch untereinander mithilfe von propriertären Protokollen kommunizieren konnten. Um die Jahrtausendwende wurden die Thin Clients mit den Rich Clients ausgetauscht. Hier war die Grundidee, dass es immer wieder Berechnungen gibt, die man am besten lokal am Client ausführt, um die Kommunikationskanäle nicht zu überlasten (Meyer 2018, 94–95).
[Webservices]Durch die erhöhte Kommunikation zwischen immer mehr Systemen wurde ein Konzept eingeführt, welches auf Services basiert, die zur Laufzeit gesucht und benutzt werden können. Somit verbreiteten sich in den 2000ern die Webservices, deren Kommunikation über den Port 80 für HTTP beziehungsweise Port 443 für HTTPS abgewickelt wird (Meyer 2018, 96).
[Cloud Computing]Seit dem Jahr 2010 hat sich Cloud Computing zu einem gängigen Verfahren entwickelt. Dabei werden die Applikationen nicht mehr auf einer statisch definierten Infrastruktur gehostet, sondern dynamisch im Netz verteilt. Dabei ist darauf zu achten, dass die Applikationen skalierbar sein müssen. Das bedeutet, dass die Applikation auch für den Einsatz von mehreren Maschinen beziehungsweise der Erweiterung von bestehenden Maschinen ausgelegt sein sollte (Meyer 2018, 101).
[Künstliche Intelligenz]Ein Schlagwort für die künstliche Intelligenz ist sicher der Turing-Test. Dabei geht es um die Einstufung der Intelligenz der Rechner. Wenn ein Mensch vor einem Rechner nicht erkennen kann, ob es sich um einen Menschen oder um eine Maschine handelt, gilt der Rechner als intelligent. Die Beschäftigung mit künstlicher Intelligenz begann schon sehr früh. In den 1950ern lag der Fokus auf wissensbasierten Systemen mit fest vorgegebenen Regeln. 1990 schlug der Schachcomputer “Deep Blue” (IBM) sogar den Schachweltmeister (Meyer 2018, 107–8).
[neuronale Netzwerke]Aus der Idee der künstlichen Intelligenz entwickelte sich der Gedanke, dass Maschinen ihre Aufgaben selbst erlernen sollen. Die Grundlage hierfür sind künstliche neuronale Netzwerke. Solche Netze können Algorithmen lernen, indem man ihnen eine Menge von Inputs und den dazu erwarteten Outputs vorgibt. Auch für das sogenannte Deep Learning werden neuronale Netze eingesetzt. Beim Deep Learning geht es darum, dass sich die Maschine selber das Wissen für einen speziellen Zweck aneignet (Meyer 2018, 108).
5.2 Softwareentwicklungsprozess
[Grundaspekte]Es wurden einige Ansätze entwickelt, damit einerseits mit der Komplexität von heutigen Softwaresystemen umgegangen werden kann und anderseits, um die Fehlerquellen zu minimieren. Diese Ansätze basieren darauf, dass der Ablauf auf nachvollziehbaren Prozessen basieren muss. Somit sollte für jeden Ablauf klar sein, was gemacht werden soll, wer verantwortlich ist und mitarbeitet, welche Voraussetzungen gelten, welche Hilfsmittel zur Verfügung stehen, welche Alternativen möglich sind und wie das Ergebnis aussehen sollte (Kleuker 2009, 7–8). Um das Ziel sowohl für EntwicklerInnen als auch KundInnen deutlicher zu machen, wird oftmals ein Prototyp erstellt. Somit soll einerseits eine Visualisierung des Ziels erfolgen, aber auch die Machbarkeit des Projektes bewiesen werden (Meyer 2018, 6).
[allgemeiner Ablauf]Generell gibt es den idealen Softwareentwicklungsprozess nicht, da jedes Projekt andere Anforderungen, Voraussetzungen, Herausforderungen und Fehlerquellen mit sich bringt. Jedoch können aus der Menge an verschiedenen Softwareentwicklungsprozessen grundlegende, gemeinsame Elemente zusammengefasst werden. Dabei handelt es sich um Spezifikation, Entwurf und Implementierung, Validation und Evolution (Sandhaus, Berg, und Knott 2014, 13). Diese allgemeinen Aktivitäten werden in den folgenden Unterkapiteln kurz näher beleuchtet.
5.2.1 Spezifikation
[Anforderungsanalyse]Bei der Spezifikation geht es um die Definition der Funktionalität und der Grenzen der Software (Sandhaus, Berg, und Knott 2014, 13). Dies beginnt mit der Anforderungsanalyse, welche grob beschreiben soll, was die Anforderungen sind. Diese Analyse wird vom Produktmanager, den SoftwareentwicklerInnen und der Kundin/dem Kunden durchgeführt. Die SoftwareentwicklerInnen werden miteinbezogen, damit bei der Beschreibung der Anforderungen bereits an die technische Umsetzung gedacht wird (Meyer 2018, 23). Dieser Schritt ist für die Qualität der Software sehr wichtig, da alle folgenden Schritte und Prozesse auf der Anforderungsanalyse basieren (Sandhaus, Berg, und Knott 2014, 18). In manchen Prozessen wird die Anforderungsanalyse noch aufgeteilt in ein Lastenheft, welches vom Kunden erstellt wird, und ein Pflichtenheft, welches vom Softwareentwickler geschrieben wird (Meyer 2018, 24).
[Konkretisierung der Spezifikation]Da in der Anforderungsanalyse die Anforderungen nur grob beschrieben werden, muss oftmals eine Verfeinerung durch eine detailliertere Beschreibung erfolgen. Diese Verfeinerung wird oft während des laufenden Prozesses erstellt (Meyer 2018, 25). Weiters sollten in dieser Phase auch noch Missverständnisse und Unklarheiten geklärt werden. Diese lassen sich unter anderem mithilfe einer Diskussion anhand von Beispielen auffinden. Aus diesen Diskussionen können dann Tests für die lauffähigen Systeme werden. Ziel ist es also, dass die Spezifikation frei von Mehrdeutigkeiten und Widersprüchlichkeiten wird (Helmke, Höppner, und Isernhagen 2007, 4).
5.2.2 Entwurf und Implementierung
EntwurfVor der Implementierung findet noch der Entwurf der Software statt. Anhand der Spezifikation wird zunächst die Anwendung modelliert und beispielsweise in kleinere Teilsysteme aufgespaltet (Kleuker 2009, 9). Die Modellierung kann mithilfe einer grafischen Repräsentation erfolgen. Diese grafische Repräsentation ist abhängig vom jeweiligen Softwareprojekt. Beispiele für grafische Modellierungstools sind UML (Unified Modeling Language) für Klassen- beziehungsweise Sequenzdiagramme oder ERM (Entity Relationship Model) für das Modellieren von relationalen Datenbanken (Meyer 2018, 29–31).
[Entwurfsprinzipien]Beim Entwuf von Software gibt es einige Prinzipien, welche die Basis bilden. Diese Prinzipien sollen oder können beim konkreten Enwurf für eine bestimmte Anwendung hilfreich sein. Dabei gibt es eine Vielzahl von Entwurfsprinzipien, welche hier nicht vollständig oder detailliert aufscheinen. Eine nähere Betrachtung ist bei Eilebrecht und Starke (2019) oder Martin und Feathers (2009) zu finden. Beispiele für Entwurfsprinzipien sind:
- Einfachheit vor Allgemeinverwendbarkeit: Statt Lösungen zu suchen, welche allgemein verwendbar und somit oft auch komplizierter sind, sollten einfache Lösungen bevorzugt werden.
- Principle of least astonishment: Besondere oder erstaunliche Lösungen sind oft nur schwer verständlich.
- Vermeiden von Wiederholungen: Unnötige Wiederholungen von Struktur und Logik sollten weitestgehend vermieden werden.
Diese Liste lässt sich beliebig mit weiteren Prinzipien, wie beispielsweise dem Prinzip der Abtrennung der Schnittstellen oder dem Prinzip solider Annahmen, fortsetzen (Eilebrecht und Starke 2019, 1–7).
[Schnittstelle zum Benutzer]Beim Entwurf sind auch schon an die direkten Schnittstellen zum Benutzer zu denken. Als solche Schnittstellen gelten unter anderem GUIs (Graphical User Interface). Zum groben Entwurf von GUIs gehört das Layout mit Menu, Scrollbar, Statusbar, Kacheln, Toolbar und Tooltips. Diese Punkte werden meist bereits in der Spezifikation zu finden sein. Beim Entwurf werden dann noch die einzelnen Elemente der GUI-Maske definiert, wie beispielsweise Buttons, Checkboxen, Dropdown-Listen, Sliders etc. Generell ist darauf zu achten, dass die Bedienbarkeit für die User (Usability) möglichst einfach ist. Wenn man GUI-lastige Systeme entwirft und implementiert, sollten Akzeptanztests durchgeführt werden, um das Feedback in den Prozess einfließen lassen zu können. Alternativen zur grafischen Oberfläche erfreuen sich seit kurzer Zeit hoher Beliebtheit und basieren auf Spracherkennung und Deep Learning. Beispiele sind Alexa (von Amazon), Cortana (von Microsoft Windows) oder Siri (von iOS) (Meyer 2018, 26–28).
ImplementierungIn der Implementierungsphase wird die Software laut Spezifikation und Entwurf umgesetzt. Schrittweise werden die kleinen Teilprogramme zu einem großen Programm zusammengesetzt. Dabei ist wichtig, dass jedes Programmteil getestet wird. Jedoch sollte nicht nur auf die Funktionalität des Teilprogramms, sondern auch auf das Zusammenspiel mit anderen Teilen getestet werden (Kleuker 2009, 9). Denn es gilt: Wenn ein kleiner Baustein nicht funktioniert, funktioniert das große System auch nicht (Helmke, Höppner, und Isernhagen 2007, 2). In früheren Zeiten wurde zumeist in herkömmlichen Editoren (zum Beispiel emacs) programmiert. Heute werden IDEs (Integrated Development Environment), wie beispielsweise Eclipse oder IntelliJ für Java verwendet (Meyer 2018, 152).
5.2.3 Validation
[Testphase]In der Validationsphase wird die Software validiert (überprüft), damit sichergestellt wird, dass die Kundenanforderungen erfüllt werden (Sandhaus, Berg, und Knott 2014, 13). Diese Validation erfolgt mittels verschiedener Testfälle, welche auf die Kundenanforderungen abgestimmt sind. Meist wird überprüft, ob typische Arbeitsabläufe möglich sind und ob Fehleingaben richtig behandelt werden (Kleuker 2009, 9).
[Kundenabnahme]Da das Ziel eines Softwareentwicklungsprojektes ist, dass der/die KundIn zufrieden mit dem Produkt ist, erfolgt auch noch eine Kundenabnahme. Der/die KundIn testet selbst die Funktionalität und Bedienbarkeit der Software. Die Kundenabnahme ist erfolgreich, wenn alle Tests erfolgreich durchgeführt werden können (Kleuker 2009, 9).
5.2.4 Evolution
[Weiterentwicklung]In der Validationsphase können entweder Probleme oder weitere Anforderungen auftreten. In der Evolutionsphase wird die Software weiterentwickelt, um den Kundenanforderungen zu entsprechen (Sandhaus, Berg, und Knott 2014, 13). Ein weiterer Grund für die Evolutionsphase ist, dass bei komplexen Systemen nicht alle Anforderungen vom Beginn an bekannt sind oder sich noch nicht definieren lassen. Außerdem können sich die Kundenwünsche auch ändern oder eben erweitern (Kleuker 2009, 9).
5.3 Vorgehensmodelle
[Grundidee]Das Ziel eines Vorgehensmodell ist es, den Softwareentwicklungsprozess zu strukturieren, indem die Gesamtaufgabe hierarchisch gegliedert wird (Sandhaus, Berg, und Knott 2014, 25). Diese Systematisierung und Strukturierung erfolgt in Form von bewährten Methodiken (best practice) (Hoffmann 2013, 493). Die Darstellung kann dabei entweder zerlegungsorientiert (mithilfe eines Baumes oder einer Hierarchie) oder ablauforientiert sein (Graph). Jede Teilphase wird dann durch einen Knoten (in der grafischen Darstellung) dargestellt. Eine Teilaufgabe hat dabei fünf Bestandteile. In den Vorbedingungen werden die Aspekte genannt, welche vor der Durchführung der Aufgabe bereits erfüllt sein sollten. Die Ergebnisse stellen die gewünschte Resultate dar und die Rückkopplung den Zusammenhang zu anderen Aufgaben. Die Aufgabe selbst beschreibt was, wann und durch wen erledigt sein muss. Weiters gibt es noch den Punkt Maße, welcher beispielsweise die Ressourcen und den Zeitfaktor betreffen (Sandhaus, Berg, und Knott 2014, 25).
[Entstehung]Durch die komplexere Software und die dadurch erhöhte Zusammenarbeit an Beteiligten (SoftwareentwicklerInnen, Projektmanger etc.) wurde in den 1990ern deutlich gemacht, dass die Vorgehensweise der Softwareentwicklung genauer definiert sein muss. Dadurch fand man Prozesse wie das V-Modell. Da es aber unmöglich ist, alle Details frühzeitig zu spezifizieren, kam das Wasserfall-Modell auf. Es folgten im Laufe der Zeit noch weitere Modelle wie beispielsweise CMM (Capability Maturity Model), RUP (Rational Unified Process), Scrum oder Kanban (Meyer 2018, 7–11). In den folgenden Unterkapiteln werden drei Modelle kurz vorgestellt.
5.3.1 Wasserfallmodell
[Entstehung]Das ursprüngliche Wasserfallmodell wurde im Jahr 1970 als eine Weiterentwicklung des Stagewise model von Beningten, von Winston W. Royce entwickelt. Jedoch hatte das Modell den Namen noch nicht. Royce bezeichnete es als “Implementation steps to develop a large program for delivery to a customer”. Der Name “Wasserfallmodell” wurde 1981 von Barry W. Boehm geprägt (Hoffmann 2013, 493; Sandhaus, Berg, und Knott 2014, 29).
[Modellbeschreibung]Das Modell sieht sieben Phasen (vgl. Abb. 5.1) vor, welche nacheinander durchlaufen werden. In zwei Phasen werden jeweils die System- und die Software-Anforderungen erstellt. Dies kann beispielsweise anhand eines Pflichtenheftes geschehen. Anschließend kommt man in die Analysephase, in welcher die Machbarkeit und Umsetzbarkeit überprüft und die Vorteile gegenüber alternativen Lösungsansätzen gesucht werden. Danach folgen die Entwurfs- und Implementierungsphasen. Nach der erfolgreichen Implementierung wird die Testphase durchlaufen. Der positive Abschluss der Testphase mündet dann in den Betrieb der Software. Im optimalen Fall müssen diese sieben Phasen nur einmal nacheinander durchlaufen werden. Praktisch tritt dieser Fall nicht immer ein und aus diesem Grund sieht Royce auch Rücksprünge in seinem Modell vor. Jedoch sind diese Rücksprünge nur in den direkten Vorgängern der Phase erlaubt. Beim positiven Abschluss einer Phase werden die Fortschritte in einem Dokument festgehalten (Hoffmann 2013, 493–94; Sandhaus, Berg, und Knott 2014, 29–31; Royce 1987, 328–34).
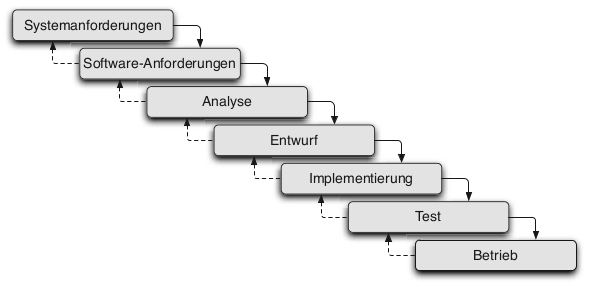
Figure 5.1: Wasserfallmodell (entnommen aus Hoffmann (2013))
[Schlüsselkonzepte]Royce verwendet in seinem Modell bereits Schlüsselkonzepte, welche in den meisten modernen Vorgehensmodellen vorhanden sind, nämlich Dokumente und Meilensteine. Da das Wasserfallmodell dokumentengetrieben ist, unterstreicht es den Fakt, dass Software oftmals aus mehr als einem Quelltext besteht (Hoffmann 2013, 494). Royce selbst meint dazu:
’how much documentation?
My own view is “quite a lot;” certainly more than most programmers, analysts, or program designers are willing to do if left to their own devices. The first rule of managing software development is ruthless enforcement of documentation requirements. [\(\dots\)] Management of software is simply impossible without a very high degree of documentation.’(Royce 1987, 332)
Das weitere Schlüsselkonzept sind Meilensteine: Durch klar definierte Meilensteine können einerseits Projektphasen getrennt, und andererseits kann der Projektfortschritt messbar gemacht werden (Hoffmann 2013, s. 495).
[Nachteile]Ein Nachteil ist die mangelnde Flexibilität, da die konsequente Abarbeitung der Phasen in der Praxis oft nicht möglich ist. Außerdem sind in der Praxis oftmals nicht alle Anforderungen an das Projekt zu Beginn bekannt. Ein weiterer Nachteil ist die strikte Trennung von Implementierung und Test. Die Testphase findet erst statt, wenn alle Implementierungen vollständig abgeschlossen sind. Jedoch zeigt sich in der Praxis, dass das frühzeitige Testen kleiner Programmabschnitte die Fehlererkennung und -behebung eindeutig erleichtert (Hoffmann 2013, 496–97).
5.3.2 V-Modell
[Modellbeschreibung]Das V-Modell kann als das erweiterte Wasserfallmodell betrachtet werden, wobei die Erweiterung die Software-Qualitätssicherung betrifft. Das V im Namen des Modells kann als zwei Stränge des Vorgehens angesehen werden (vgl. Abb. 5.2). Der absteigende Strang arbeitet dieselben Phasen wie das Wasserfallmodell ab, der aufsteigende Strang testet jeden Entwicklungsschritt und ist somit für die Qualitätssicherung zuständig. In diesem Modell wird das Vorgehen durch einheitliche und verbindliche Aktivitäten mit deren jeweiligen Ergebnissen klar strukturiert. Jede Aktivität ist genau dokumentiert und kann als Arbeitsanleitung angesehen werden. Seit der Einführung des Modells im Jahr 1992 wurde es öfter überarbeitet und erweitert. Momentan wird das V-Modell XT verwendet, wobei XT für eXtreme Tailoring steht. In dieser Erweiterung bleibt das V-förmige Vorgehen bestehen, jedoch haben die einzelnen Schritte nur wenig mit dem ursprünglichen Modell gemeinsam (Hoffmann 2013, 496–98; Sandhaus, Berg, und Knott 2014, 31–32).

Figure 5.2: V-Modell (entnommen aus Hoffmann (2013))
ValidationDas Modell unterscheidet die Begriffe Verifikation und Validation, wobei bei der Validation die Spezifikation des Produktes bezogen auf den geplanten Einsatzzweck überprüft wird. Dabei spielt es für die Validation keine Rolle, ob die Softwareentwicklung die Spezifikation fehlerfrei umgesetzt hat. Es geht um die Tauglichkeit und die Frage, ob das entwickelte System den Anforderungen und Wünschen der Kunden entspricht (Hoffmann 2013, 497).
[Verifikation]Im Gegensatz zur Validation steht die Verifikation. Hier wird überprüft, ob die Spezifikation von der erstellten Software erfüllt wird. Dabei wird die Spezifikation als korrekt vorausgesetzt. Somit fallen die klassischen Software-Tests ausschließlich in den Bereich der Verifikation (Hoffmann 2013, 497).
5.3.3 Extreme Programming
[Grundidee]Schon das Wasserfallmodell war dokumentenlastig und auch die nachfolgenden Modelle erforderten immer mehr Zeit zum Einarbeiten durch Durchlesen der Dokumente. Als Gegenpol wurden agile Modelle entwickelt, welche versuchten, die komplexe Arbeitsabläufe durch wenige, aber flexibel anwendbare Regeln zu ersetzen. Die agilen Modelle sind darauf ausgerichtet, auf unvorhergesehene Änderungen schnell und flexibel reagieren zu können. Ein Vertreter der agilen Modelle ist das Extreme Programming (XP). Dieses wurde von Kent Beck, Howard Cunningham und Ron Jeffries entwickelt. Hinter XP stehen fünf zentrale Werte, nämlich Kommunikation, Einfachheit, Rückmeldung, Mut und Respekt (Hoffmann 2013, 506–7; Sandhaus, Berg, und Knott 2014, 8).
[Kommunikation]Durch die Zusammenarbeit vieler entsteht schlussendlich die Software. Zusammenarbeit kann aber nur mithilfe guter Kommunikation funktionieren. Viele Fehler und Probleme lassen sich auf mangelhafte Kommunikation zurückführen. Basierend auf dieser Erkenntnis definiert XP Arbeitsabläufe, bei denen ein hohes Maß an Kommunikation benötigt wird. Wie beispielsweise Pair Programming, also das Programmieren gemeinsam in Paaren (Hoffmann 2013, 507).
[Einfachheit]Wie bereits bei den Entwurfprinzipien (vgl. 5.2.2 Entwurf und Implementierung) beschrieben, sollte man sich stets auf die einfachste Lösung konzentrieren. Die Schwierigkeit Software zu entwickeln sollte nicht künstlich erhöht werden. Denn “[w]ird an den richtigen Stellen auf unnötige Komplexität verzichtet, kann zum einen die Anzahl der Fehler reduziert und zum anderen das gleiche Produkt in deutlich geringerer Zeit entwickelt werden.”(Hoffmann 2013, 507)
[Rückmeldung]Nicht nur die Kommunikation ist ein wichtiger Teil von XP, sondern auch die Rückmeldung, sodass zu jeder Zeit der aktuelle Zustand des Projekts beschrieben werden kann. Aus diesem Grund setzt sich die Rückmeldung aus dem System-Feedback, welches durch Unit-Tests entsteht, dem Kunden-Feedback, welches durch Akzepttanztest erstellt wird, und dem Team-Feedback, welches bei Änderungswünschen direkt vom Team eingeholt wird, zusammen (Hoffmann 2013, 507–8).
[Mut]Der Mut betrifft Änderungen der Systemarchitektur. Auch wenn diese Änderungen einen großen Aufwand verursachen, gilt beim XP, dass nicht an suboptimalen Implementierungen oder Architekturen festgehalten wird. Hinter dieser Idee steckt, dass die Produktqualität eine wichtige Rolle für den Projekterfolg spielt (Hoffmann 2013, 507).
[Respekt]Das Gelingen eines Projektes hängt vom gesamten Team ab. Dabei spielen Aspekte wie Motivation oder auch Teamgeist eine große Rolle. Um ein gutes Team zu bilden, benötigt man auch Respekt untereinander, aus diesem Grund hat dieser auch einen wichtigen Platz bei Extreme Programming (Hoffmann 2013, 507).
[Best practices]Insgesamt lassen sich aus diesen fünf Werten einige Vorgehensweisen ableiten. Jedoch werden nicht alle Regeln auch in der Praxis umgesetzt. Einige Ideen haben sich aber bewährt, wie beispielsweise:
- The Planning Game: Im Planungsspiel geht es um die Festlegung der Rahmendaten für den nächsten Schritt oder das nächste Release. Diese Planung wird mit dem gesamten Team, also auch mit Einbezug der Kunden, erstellt.
- Pair Programming: Beim Pair Programming arbeiten, wie der Name schon sagt, zwei Entwickler gemeinsam am Source Code. Dabei haben diese unterschiedliche Rollen. Während sich eine der Personen um die Implementierung kümmert, denkt sich die andere Person diesen Ansatz auf abstrakter Ebene durch und hilft Fehler oder Schwierigkeiten aufzudecken. Vor allem bei zentralen Modulen kann es sinnvoll sein, Pair Programming einzusetzen.
- Continuous Integration: Bei der fortlaufenden Integration soll der erstellte Programmcode in den bestehenden Source Code integriert werden. Da vor dieser Integration die Unit-Tests durchgeführt werden, kann die Entwicklung nur fortgesetzt werden, wenn diese Testfälle fehlerfrei funktionieren. Dadurch wird die Fehlersuche eingegrenzt, da nur bestimmte Funktionalitäten beziehungsweise Programmteile beachtete werden müssen (Hoffmann 2013, 509–14; Meyer 2018, 8).
5.4 Pattern
[Hintergrund]Das englische Wort Pattern bedeutet auf Deutsch Muster und sagt eigentlich schon alles über die Grundidee von Pattern aus. Pattern beschreiben Lösungsansätze oder Vorgehen, welche in der Softwareentwicklung immer wieder vorkommen. Die Idee der immer wiederkehrenden Muster wurden von der “Gang of Four” beschrieben. In ihrem veröffentlichten Buch Design Patterns beschrieben sie Muster, welche häufig in objektorientierten Softwareprojekten verwendet wurden (Meyer 2018, 188). Da es eine Vielzahl von Design Pattern gibt, werden im Folgenden nur ausgewählte Pattern kurz umrissen. Ausführliche Beschreibungen sind beispielsweise bei Eilebrecht und Starke (2019), Meyer (2018) oder Gamma u. a. (2011) zu finden.
[Observer]Bei einer Software hängen beispielsweise bestimmte Outputs von der Auswahl von Parametern ab. Zum Beispiel öffnet sich bei einer GUI ein weiteres Fenster, wenn man auf einen Button klickt. Da eine solche Abhängigkeit entsteht, sollte sich der Output bei Paramteränderungen auch anpassen. Einen Mechanismus für dieses Anpassung liefert das Pattern Observer. Mithilfe des Observers können mehrere Objekte (\(\geq 1\) Objekt(e)) automatisch auf eine Änderung eines anderen Objektes reagieren und den Zustand anpassen. Dieses Vorgehen ist auch unter dem Begriff Publish/Subscribe bekannt. Vorteile von Observern sind, dass die abhängigen Objekte automatisch ihren Zustand anpassen und dass nicht im Voraus schon bekannt sein muss, wieviele abhängige Objekte es im Laufe des Source Codes gibt. Da die Komplexität eines observierenden Objektes steigen kann und nicht immer klar ist, welcher Observer die anderen Objekte benachrichtigt hat, sind zwei der Nachteile von Observern (Eilebrecht und Starke 2019, 70–73; Meyer 2018, 188; Gamma u. a. 2011, 293–94).
[Lazy Load]Im Programmlauf müssen oftmals umfangreiche Objekte bereitgestellt werden. Solche Operationen können aber sehr teuer – bezogen auf Performance, Speicher, etc. – sein. Außerdem kann es auch sein, dass dann nicht alle gelieferten Informationen tatsächlich genutzt werden. Um diesem Problem gegenzuwirken, wurde das Pattern Lazy Load, also verzögertes Laden, erstellt. Die Grundidee ist dabei, dass ein Objekt die Daten erst lädt, wenn sie wirklich benötigt werden. Ein großer Vorteil von Lazy Load ist, dass Ladezeit eingespart und somit die Performance nicht beeinträchtigt wird. Ein Nachteil ist, dass die Komplexität durch die Nachladestrategie, welche implementiert sein muss, steigt (Eilebrecht und Starke 2019, 156–57; Meyer 2018, 188).
[Null-Objekt]Innerhalb der Software werden oftmals Datenstrukturen verwendet, welche im Programmlauf mit Daten gefüllt werden. Dadurch muss aber überprüft werden, ob Daten in der Datenstruktur vorhanden sind, um mit diesen weiterarbeiten zu können. Falls eine Datenstruktur leer ist, aber man im Programm trotzdem auf die Daten zugreifen möchte, endet dies meistens in einem Fehler, welcher auch das komplette Programm abstürzen lassen kann. Damit man dieses Problem in den Griff bekommt, entstand das Pattern Null-Objekt. Dabei handelt es sich um eine Klasse, die “nichts” macht. Wobei das “Nichts” fachlich ist. Beispielsweise kann mit diesem Pattern geprüft werden, ob eine linked list mit Namen \(linkedL\) leer ist: if(\(linkedL\) == null)\(\{\dots\}\). Durch die Abfragen mittels Null-Objekt wird der Code lesbarer, was ein Vorteil ist. Ein Nachteil kann jedoch entstehen, wenn nachträglich ein Null-Objekt eingeführt wird, da dann an vielen Stellen im Quellcode Änderungen benötigt werden (Eilebrecht und Starke 2019, 190–92).
[Singelton]In manchen Kontexten ist es sinnvoll, dass nur eine Instanz einer Klasse existiert. Mit dem Pattern Singelton wird so ein Vorgehen ermöglicht. Singelton stellt sicher, dass nur genau eine Instanz einer Klasse erzeugt werden kann. Somit kann Singelton auch als Ersatz für globale Variablen gesehen werden, da diese, wenn möglich, vermieden werden sollten. Ein Vorteil ist, dass Singelton leicht anwendbar ist. Jedoch kann es bei multi-threaded Anwendungen zu Problemen kommen, da es beispielsweise zu einer Engstelle werden kann, wenn alle Threads darauf zugreifen. Somit wird die Performance verringert (Eilebrecht und Starke 2019, 38–40; Meyer 2018, 188).
[Factory Method]Wenn Objekte erzeugt werden sollen, ohne die konkrete Klasse davor zu kennen oder diese erst später festzulegen, kann das Pattern Factory Method angewandt werden. Dabei wird eine Schnittstelle (Interface) zur Erzeugung von Objekten definiert, wobei die Implementierung des Interface entscheidet, welche konkrete Klasse instanziiert wird. Ein Vorteil ist, dass der Creator austauschbar und für den Client nur die Schnittstelle von Bedeutung ist. Ein Nachteil ist, dass der Creator stark an bestimmte Verwendungsmöglichkeiten (zum Beispiel für konkrete Produkte) gekoppelt ist, somit muss bei neuen Verwendungsmöglichkeiten die Implementierung des Creators angepasst werden (Eilebrecht und Starke 2019, 34–36; Meyer 2018, 188).
[Anti-Patterns]Beim Programmieren treten leider nicht nur gewollte und gewünschte Patterns wie die oben beschriebenen auf, sondern auch unerwünschte Muster, also Anti-Patterns. Dazu gehören unter anderem: Bad Comments, No Comments, also fehlende oder ungünstig gewählte Kommentare, oder Dead Code, dies ist unnötiger Code, der nicht gelöscht wird. Außerdem kann noch Duplicated Code oder Copy-Paste-Code auftreten, dabei handelt es sich um Code, welcher öfter kopiert und an anderen Stellen im Source Code eingefügt wird, anstatt diesen in eine Funktion oder Methode auszulagern (Meyer 2018, 201).
5.5 Softwarequalität
[Definition]Softwarequalität lässt sich nicht mit einem bestimmten Kriterium verbinden, da dahinter einige Kriterien stecken. Jedoch entwickelt jede/r Programmierer/in ein intuitives Verständnis für Softwarequalität. Laut der DIN-ISO-Norm 9126 wird Softwarequalität wie folgt definiert:
“Software-Qualität ist die Gesamtheit der Merkmale und Merkmalswerte eines Software-Produkts, die sich auf dessen Eignung beziehen, festgelegte Erfordernisse zu erfüllen.”
Diese Definition zeigt nochmals auf, dass es eben nicht das Kriterium zum Beschreiben von Softwarequalität gibt. Außerdem variieren die Kriterien je nach Anwendungsgebiet und/oder den gestellten Anforderungen (Hoffmann 2013, 6; Masak 2010, 27–28).
[Kriterien]Die Kriterien lassen sich in kundenorientierte und herstellerorientierte Merkmale einteilen. Kundenorientierte Qualitätsmerkmale sind Funktionalität, Zuverlässigkeit, Effizienz und Benutzbarkeit. Die Kriterien Übertragbarkeit, Änderbarkeit, Testbarkeit und Transparenz sind herstellerorientiert (Hoffmann 2013, 7; Liggesmeyer 2009, 5–6).
[Functionality, Capability]Die Funktionalität beschreibt, inwieweit die Software den Anforderungen entspricht. Funktionale Fehler können in der Umsetzung entstehen oder durch falsch verstandene Spezifikationen. Außerdem sind diese Fehler allgegenwärtig und die Softwarequalität wird oftmals nur noch auf dieses Kriterium reduziert (Hoffmann 2013, 7; Masak 2010, 29).
[Performance]In den meisten Fällen wird die Laufzeit nicht explizit in der Spezifikation beschrieben, dennoch müssen gewisse Laufzeitanforderungen eingehalten werden. Vor allem bei Echtzeitsystemen unterliegen alle getätigten Operationen bestimmten Zeitanforderungen, welche eingehalten werden müssen. In solchen Fällen ist die Performance stark mit der Funktionalität verwoben und beide haben die gleich wichtige Bedeutung (Hoffmann 2013, 7).
[Dependability, Reliability]Software wird heutzutage nahezu überall eingesetzt. Durch den Einsatz in sicherheitskritischen Anwendungen wie in PKWs, Flugzeugen oder roboterunterstützer Chirurgie muss die Software auch zuverlässig sein. In solch kritischen Bereichen kann jedes Systemversagen katastrophale Folgen haben. Doch auch in anderen Bereichen sollte die Software zuverlässig arbeiten. Diese Zuverlässigkeit geht oft Hand in Hand mit der Optimierung anderer Kriterien. Die Zuverlässigkeit kann mithilfe von stochastischen Techniken beschrieben werden. Beispielsweise wird als Mean Time to Failure (MTTF) der Erwartungswert für die Zeitspanne bis zum Ausfall eines Systems angegeben (Hoffmann 2013, 8; Liggesmeyer 2009, 7–8).
[Usability]Die Benutzbarkeit spielt bei der Software eine Rolle. Jedoch kann diese an die Anforderungen angepasst werden. So wird bei weit verbreiteter Software der Bedienbarkeit ein großes Gewicht zugeordnet. Im Fall einer kaum oder nur von abgezählten ExpertInnen verwendeten Software, verliert die Bedienbarkeit an Gewicht. Bei der Benutzbarkeit stellt sich die Frage: Welcher Aufwand wird von den Benutzern für den Einsatz der Software gefordert?(Hoffmann 2013, 8; Masak 2010, 29)
[Maintainability]Schon im Softwareentwicklungsprozess wird die Evolution, also das Weiterarbeiten an der Software, genannt. Um eine Software weiterzuentwickeln oder Fehler auszubessern, sollte der Source Code möglichst wartbar sein. Diese Änderungen können Korrekturen, Verbesserungen, Weiterentwicklungen etc sein. Jedoch ist die Wartbarkeit von Software auch ein Qualitätsmerkmal, welches das Produkt längerfristig marktfähig macht (Hoffmann 2013, 8; Masak 2010, 30).
[Transparency]Bei der Transparenz stellt sich die Frage, wie die Programmfunktionalität intern umgesetzt wurde. Handelt es sich dabei um ein strukturiertes, verständliches Programm? Ziel ist natürlich ein gut strukturiertes Programm, jedoch wird gerade bei der Weiterentwicklung Unordnung in den Code gebracht. Diese Unordung wird auch als Software-Entropie bezeichnet (Hoffmann 2013, 8–9).
[Portability]Die Struktur der Informatik ist langsam gewachsen, deshalb gibt es auch keine einheitlichen Umgebungen. Aus diesem Grund stellt sich die Frage nach der Übertragbarkeit von Software in andere Umgebungen. Diese Umgebungen können verschiedene Architekturen (beispielsweise 32-Bit- oder 64-Bit-Architekturen), Betriebssysteme etc. sein (Hoffmann 2013, 9; Masak 2010, 31).
[Testability]Da Software zuverlässig sein sollte, sollte es möglich sein, die Softwarefehler zeitnah zu erkennen und zu beheben. Aus diesem Grund ist die Testbarkeit auch ein Qualitätskriterium. Dieses Kriterium wird jedoch durch die Komplexität erschwert, welche sogar bei kleineren Programmen so groß sein kann, dass es unmöglich ist, alle möglichen Fälle zu testen (Hoffmann 2013, 9).
[Softwaretests]Somit gehören klassische Softwaretests zur Qualitätssicherung dazu. Vor allem wenn man Murphy’s Law im Hinterkopf behält, welches aussagt: Wenn irgendetwas schief gehen kann, wird es auch schief gehen (Meyer 2018, 20). Bei diesen Tests wird das Programm mit vordefinierten Eingabewerten ausgeführt und der Output mit Referenzergebnissen abgeglichen. Da nicht alle Testfälle behandelt werden können, muss man sich auf eine vergleichsweise geringe Menge an Testfällen beschränken (Hoffmann 2013, 22). Bei den klassischen Tests gibt es zwei Philosophien: den White-Box- und den Black-Box-Test. Beim Black-Box-Testing sind nur die Schnittstellen bekannt, aber nicht deren vollständige Implementierung. Hingegen kennt man beim White-Box-Test auch die internen Details. Beispiel für Tests sind Integration-Tests, welche überprüfen, ob die Module zusammenpassen, Systemtests für die Funktionalität, Unit-Tests, um einzelne Komponenten zu testen und Akzepttanztests, bei welchen Benutzer die GUI beurteilen (Meyer 2018, 242).
[Software-Verifikation]Bei den klassischen Tests werden nur einige ausgewählte Testfälle getestet, bei der Softwareverifikation wird auf mathematischem Weg versucht das Programm formal zu beweisen. Dieser formale Ansatz hat das Ziel, die vollständige Korrektheit einer Software zu beweisen. Diese Methode existiert schon länger im akademischen Umfeld, wird aber nur in wenigen Ansätzen auch in der Industrie genutzt. Dies kann unter anderem daran liegen, dass bereits bei sehr kleinen Programmen äußerst rechenintensive Algorithmen angewendet werden müssen. Mit dem Ansatz der semi-formalen Verifikation wird eine mathematische Betrachtung bewahrt, jedoch wird bewusst auf die hundertprozentige Korrektheit verzichtet. Aus diesem Grund lassen sich semi-formale Verifikationsmethoden auch in der Praxis umsetzen (Hoffmann 2013, 24).