Kapitel 6 Entwickelte App
Wie bereits erwähnt, wurden die Stufenmodelle von Biehler und Prömmel (2013) und Riemer (1991) von Simulationen begleitet. Aus diesem Grund mündet der theoretische Input dieser Arbeit auch in eine Simulation. Im folgenden Kapitel sind kurz die Entwicklungsschritte umrissen, welche zur App führten. Die Unterkapitel gliedern sich nach dem Softwareentwicklungsprozess (Sandhaus, Berg, und Knott 2014, 13).
6.1 Spezifikation
[Stufenmodell als Basis]Die Funktionalität der entwickelten App basiert auf dem beschriebenen Stufenmodell von Biehler und Prömmel (2013). Durch die detaillierte Beschreibung des Modells (vgl. Stufenmodell) muss die Funktionalität der App nicht noch verfeinert werden. Das Ziel ist eine funktionstüchtige App, welche im Schulkontext zur Erklärung von Zufall, dem empirischen Gesetz der großen Zahlen und dem \(\frac{1}{\sqrt{n}}\)-Gesetz eingesetzt werden kann.
[Zielgruppe]Durch den geplanten Einsatz in den Schulen sind vor allem SchülerInnen und Lehrpersonen die Zielgruppe dieser App. Schlussendlich soll die App einen sinnvollen Beitrag zum Unterricht bieten und diesen unterstützen, veranschaulichen oder abrunden. Eine Alterseinschränkung bezüglich der SchülerInnen gibt es per se nicht, jedoch werden von Biehler und Prömmel (2013) die Klassenstufen 6 bis 12 vorgeschlagen. Mit Blick auf das Stufenmodell wird ersichtlich, dass manche Inhalte bereits früh in den Unterricht eingebunden werden können, wie beispielsweise die Entwicklung für wachsendes \(n\). Inhalte, wie die theoretische Behandlung inklusive der Verbindung mit den \(\sigma\)-Regeln benötigen jedoch mehr Vorarbeit und Vorwissen.
[Web-App]Um den Einsatz der App zu erleichtern, soll es eine webbasierte App werden. Ein Vorteil von Web-Apps ist, dass diese mit allen Betriebssystemen funktionieren. Außerdem kann die App ohne Installation direkt genutzt werden („Native Apps vs. Web Apps - Unterschiede und Vorteile“ 12.06.2019). Im Schulkontext bedeutet dies, dass die App auch spontan im Unterricht eingesetzt werden kann. Ein weiterer positiver Aspekt ist, dass die Web-Apps in Sekundenschnelle veröffentlicht und aktualisiert werden können („Native Apps vs. Web Apps - Unterschiede und Vorteile“ 12.06.2019). Die App wird außerdem auch ohne irgendwelche Anmeldungen oder Erstellen von Benutzerkonten nutzbar sein.
[gesetzte Ziele]Die Zielvorgaben sind einerseits durch das Stufenmodell abgedeckt. Doch soll dieses noch durch eine veränderbare Wahrscheinlichkeit für das Ereignis “Kopf”, veränderbare Quantile, etc. erweitert werden. Dadurch ist es auch möglich “gezinkte” Münzen zu betrachten oder die App vom Kontext Münzwurf zu lösen und beliebige dichotome Zufallsvariablen zu behandeln. Der Einsatz der App ist auch nicht losgelöst vom Unterricht zu sehen, die App dient eher der Unterstützung des Unterrichts durch mögliches Ausbilden von intuitiven Zugängen und Vorstellungen. Weiters müssen in höheren Stufen die Konzepte Quantile, Binomialverteilung, Sigma-Regeln, Normalapproximation, etc. bereits bekannt sein, da die App darauf zurückgreift.
6.2 Entwurf und Implementierung
[R Shiny]Im Bereich Entwurf und Implementierung findet sowohl die Modellierung als auch die Umsetzung der Software statt (Kleuker 2009, 9). Da sowohl der Entwurf als auch die Implementierung bei der entwickelten App stark von der Programmiersprache abhängen, wird diese kurz beschrieben. R Shiny ist eine Erweiterung von R, welche es einfach macht, interaktive Web-Apps zu entwickeln. Als Kernaspekte gelten dabei:
- Es wird kein JavaScript benötigt, jedoch kann es verwendet werden.
- Die Interfaces können in R oder direkt in HTML und CSS aufgebaut werden.
- Es gibt eine große Anzahl an prebuilt Input- und Outputformaten, wie Slider, Plots, Tabellen etc.
- R Shiny erlaubt eine schnelle bidirektionale Kommunikation zwischen dem Web-Browser und R, welches im Hintergrund läuft.
- R Shiny verwendet reactive programming, somit wird der event handling code reduziert.
R Shiny-Apps benötigen jedoch einen Shiny Server, um veröffentlicht zu werden (Chang 2019a).
[Vorgehensmodell]Für den Entwurf und die Implementierung wurde das Vorgehensmodell “Wasserfallmodell” (vgl. 5.3 Vorgehensmodelle) in leicht veränderter Form verwendet. Die Implementierungsphase wurde auf die insgesamt fünf Stufen aufgeteilt und erst nach positiven Durchlaufen einiger manueller Tests einer Stufe, wurde die nächste Stufe implementiert. Am 6. Mai 2019 wurde zwar ein Package für das Testen von Shiny Apps entwickelt (vgl. Chang 2019b) jedoch wird bei dieser App nicht auf das automatisierte Testen mit shinytest() zurückgegriffen. Weiters ist sowohl der Entwurf als auch die Implementierung nicht stark dokumentengetrieben. Einerseits liegt es daran, dass kein Team an Entwicklern daran arbeitete und andererseits, da direkt im Code dokumentiert wurde.
6.2.1 Entwurf
[Entwuf exemplarisch]Bei der Beschreibung des Modellierungsvorgangs beim Entwurf wird exemplarisch eine Stufe des Stufenmodells, nämlich der Schwankungsvergleich für zwei verschiedene \(n\) ausführlich behandelt. Alle weiteren Stufen wurden analog bearbeitet.
[geforderte Funktionalität]Die geforderte Funktionalität für diese Stufe ist das Darstellen des prozentuellen Anteils für das Ereignis Kopf beim Münzwurf in zwei Serien. Dabei wird eine Serie mit einer geringen Münzwurfanzahl und die andere mit einer hohen Münzwurfanzahl durchgeführt. Außerdem wird noch die Abweichung vom vermeintlichen Erwartungswert \(n/2\) der absoluten Häufigkeiten beleuchtet (Biehler und Prömmel 2013, 18–19). Zur näheren Betrachtung werden auch die relativen und absoluten Häufigkeiten tabellarisch dargestellt, um eine weitere Visualisierung zu geben.
[Entwurf der GUI]Da es sich um eine GUI-lastige Anwendung handelt, ist auch der Entwurf des general user interface bereits beim Entwurf mitzudenken. Um der App ein grundlegendes Design zu geben, ist das Layout jeder Stufe gleich aufgebaut. Links ist ein Sidebar-Panel, welches die veränderbaren Parameter umfasst. Der restliche Bereich ist für den Inhalt wie Text, Plots etc. vorgesehen. Auch diese Stufe folgt dem Schema (vgl. Abb. 6.1). Hier ist klar ersichtlich, dass die Input-Parameter im grau hinterlegten Sidebar-Panel zu finden sind. Die Aufteilung des Hauptbereichs soll die Platzhalter für den dynamischen Output wiederspiegeln.
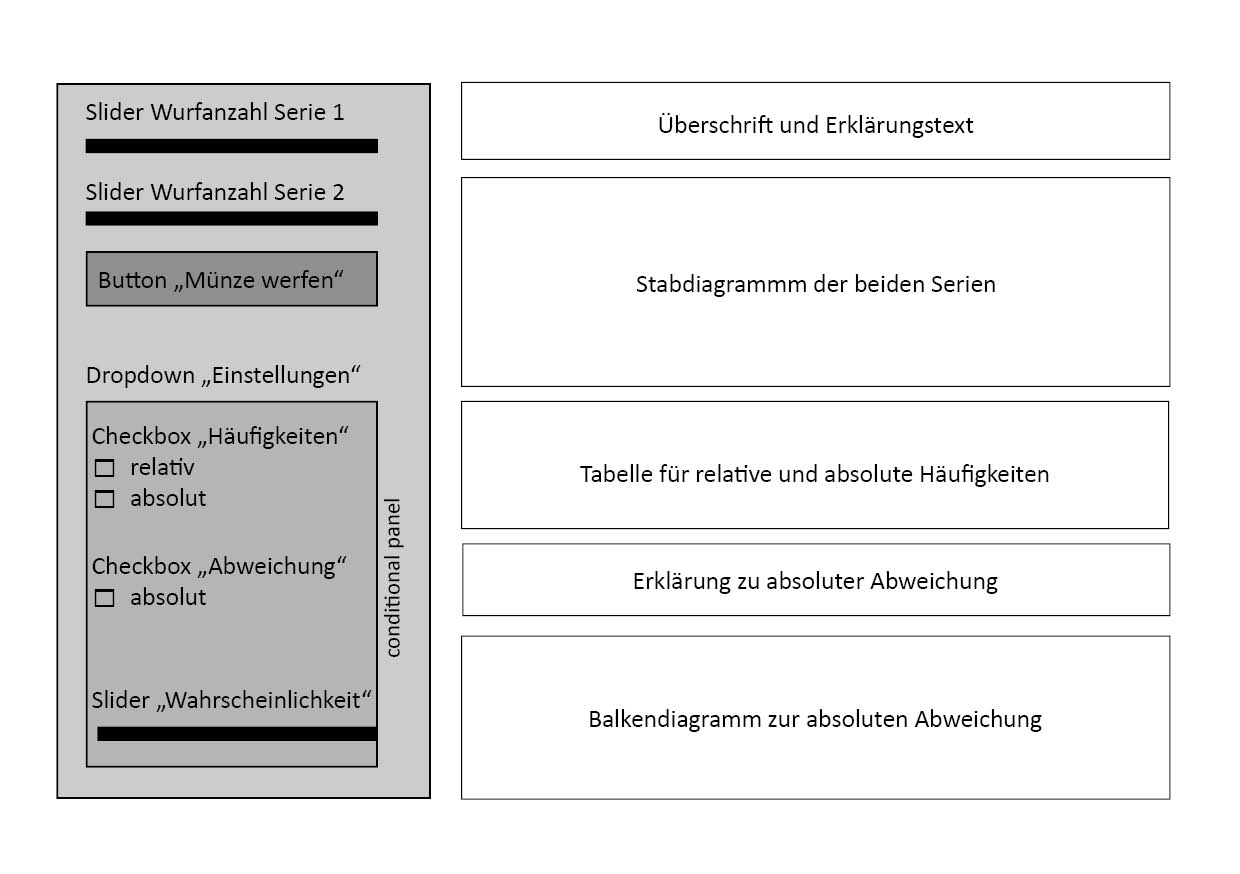
Figure 6.1: Rohentwurf der GUI
[Beschreibung der Elemente]Zur Modellierung der GUI gehören auch die Beschreibung der Elemente und ihre Abhängigkeiten untereinander. Die Elemente werden kurz im Folgenden umrissen. Die Abhängigkeiten werden zusätzlich noch in Abb. 6.2 grafisch dargestellt.
- Slider Wurfanzahl Serie 1: Die Serie 1 hat geringere Münzwurfanzahlen, aus diesem Grund sind die Grenzen für den Slider 5 und 20, wobei der Slider in 1er Schritten weiter verschoben werden kann. Um den Zusammenhang zum Output darzustellen, soll der Slider rot eingefärbt sein. Dieser Slider nimmt Einfluss auf die Output-Elemente Stabdiagramm der beiden Serien, Tabelle für relative und absolute Häufigkeiten, Erklärungen zu absoluter Abweichung und Balkendiagramm zur absoluten Abweichung.
- Slider Wurfanzahl Serie 2 Der Slider ist im Intervall von [200;500] in 1er Schritten verstellbar, da die Serie 2 einen Münzwurf mit höherer Münzwurfanzahl darstellt. Dieser Slider soll blau eingefärbt werden. Der Slider der Serie 2 hat den gleichen Einfluss auf die Output-Elemente wie der Slider der Serie 1.
- Button “Münze werfen”: Durch Klick auf den Button sollen die Input-Parameter eingelesen beziehungsweise upgedatet werden. Mit den geänderten Werten, werden die Zufallsexperimente erneut durchgeführt. Dadurch nimmt der Button Einfluss auf den gesamten Output.
- Dropdown “Einstellungen”: Mithilfe der Dropdown-Liste Einstellungen kann zwischen den “Basis”- und den “Erweiterten”-Optionen gewählt werden. Standardmäßig ist “Basis” ausgewählt. Beim Wechseln zwischen den Einstellungsarten bleiben alle gewählten Einstellungen erhalten.
- Checkbox “Häufigkeiten”: Die Checkbox lässt eine Mehrfachauswahl zwischen der relativen und der absoluten Häufigkeit zu. Die absolute Häufigkeit wird in der Tabelle für relative und absolute Häufigkeiten dargestellt. Wenn nur die relative Häufigkeit ausgewählt ist, wird diese direkt im Stabdiagramm der beiden Serien dargestellt. Sind beide Häufigkeiten ausgewählt, dann wird die relative Häufigkeit sowohl in der Tabelle als auch im Stabdiagramm dargestellt.
- Checkbox “Abweichung”: Ohne Aktivierung dieser Checkbox scheinen die Erklärung zur absoluten Abweichung und das Balkendiagramm zur absoluten Abweichung nicht auf.
- Slider “Wahrscheinlichkeit”: Mithilfe des Sliders lässt sich die Wahrscheinlichkeit für das Ereignis “Kopf” einstellen. Dadurch können auch gezinkte Münzen oder andere dichotome Zufallsvariablen betrachtet werden. Dieser Slider beeinflusst das Stabdiagramm der beiden Serien und die Erklärung zu absoluter Abweichung.
- Überschrift und Erklärungstext: Dieser Output kümmert sich um die Überschrift und den Erklärungstext zur Stufe und benötigt keinen Input.
- Stabdiagramm der beiden Serien: Im Stabdiagramm werden die relativen Häufigkeiten der beiden Serien für das Ereignis “Kopf” dargestellt. Serie 1 scheint in rot auf und Serie 2 in blau, sodass die Farben äquivalent zu den Sliderfarben sind. Input für den Plot sind die Slider zu den Wurfzahlen und zur Wahrscheinlichkeit.
- Tabelle für relative und absolute Häufigkeiten: Die Tabelle reagiert automatisch auf die Auswahl der Checkbox “Häufigkeit”. Je nach Auswahl werden entweder die Wurfanzahlen, die absoluten und die relativen Häufigkeiten oder die Wurfanzahlen und die absoluten Häufigkeiten dargestellt. Einfluss auf diese Tabelle haben die Slider zu den Wurfzahlen und zur Wahrscheinlichkeit.
- Erklärung zu absoluter Abweichung: Die Erklärung ist eine dynamischer Text, welcher die Slider der Wurfanzahlen und der Wahrscheinlichkeit miteinbezieht.
- Balkendiagramm zur absoluten Abweichung: Das Balkendiagramm zeigt die absolute Abweichung vom vermeintlichen Erwartungswert \(n/2\) der absoluten Häufigkeiten. Dabei wird die absolute Häufigkeit minus dem Erwartungswert berechnet, um die Schwankungen gut darstellen zu können.
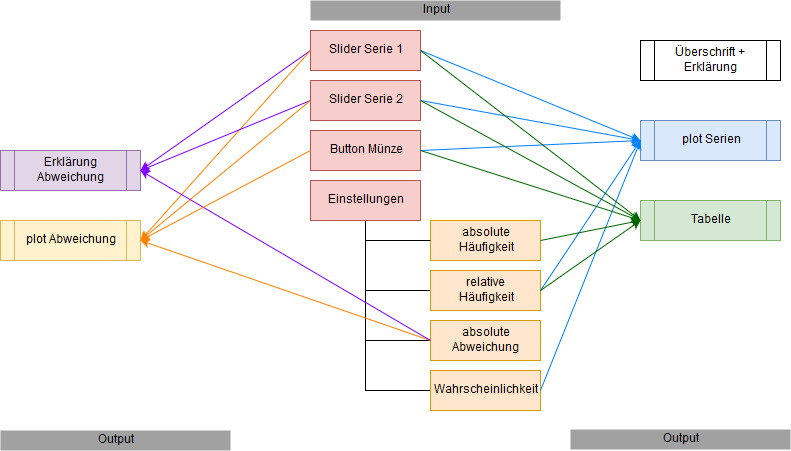
Figure 6.2: Abhängigkeiten der GUI Elemente
[Abhängigkeiten]Die Abhängigkeiten der acht Input- und fünf Output-Elemente untereinander sind in Abb. 6.2 nochmal grafisch dargestellt. Zur leichteren Übersicht sind die benötigten Input-Daten (dargestellt mittels Pfeilen) farblich passend zum Output-Element eingezeichnet. Anhand der Grafik erkennt man, dass die Elemente untereinander stark vernetzt sind.
6.2.2 Implementierung
[Aufbau einer Shiny App]Eine Shiny-App besteht grundsätzlich aus zwei Komponenten. Für das Layout und das general user interface ist beispielsweise die Datei ui.R zuständig. Die Funktionalität liefert dann server.R. Es gibt auch die Möglichkeit sowohl das Layout als auch die Funktionalität in einer Datei zu implementieren (Chang 2019a). Jedoch verliert der Code bei größeren Apps dann schnell an Übersichtlichkeit. Aus diesem Grund ist die entwickelte App auch in die zwei oben genannten Dateien aufgeteilt.
[Aufbau der App]Die Grundüberlegung zum Layout jeder einzelnen Stufe ist bereits im Unterkapitel Entwurf beschrieben und in Abb. 6.1 visualisiert. Diese Modellierung wird für den Aufbau der App beibehalten. Zusätzlich wird noch eine Navigationsleiste mithilfe von navbarPage(), tabPanel() und navbarMenu() (vgl. Chang (2019a)) das optische Gestaltungsbild prägen und die Bedienung und Orientierung in der App vereinfachen.
[Strukturierung des Codes]Durch die Verwendung von nur einem Source Code für das Layout und einem für die Funktionalität entwickelte ich ein Namenssystem, um die fünf Stufen (inklusive untergeordneter Schritte) einfach innerhalb des Codes zu unterscheiden und eindeutig zuordnen zu können. Input-Elemente wurden dabei mit ihrer Funktion und der Nummer der zugehörigen Stufe benannt. Dabei beschreibt die letzte Zahl immer die Hauptstufe. Beispielsweise:
sliderInput("n12", label = "Wurfanzahl",
min = 0, max = 1000, value = 300,
step = 1, ticks = FALSE)Dieser Slider beschreibt die Wurfanzahl (Stichprobenumfang \(n\)) in der Stufe 2 im untergeordnetem Schritt 1. Somit sind die Input-Elemente eindeutig benannt. Mithilfe von reactiveValues() (vgl. Chang (2019a)) können Variablen direkt auf Änderungen reagieren und halten den momentan gewählten Wert der Input-Elemente der App. Um die Lesbarkeit des Codes zu erhöhen, wurde für jede Stufe eigene reactiveValues() erstellt.
val2 <- reactiveValues(
n1 = 300,
amount1 = 2,
vecRel = c(),
...
)So sind beispielsweise die benötigten Werte der Stufe 2 in val2 zu finden. Im Code werden diese dann beispielsweise durch val2$n1 für den oben beschriebenen Slider angesprochen.
[Observer]Bereits bei der Beschreibung der Pattern (vgl. Pattern) wurde der Observer genannt. Mithilfe des Observers können Objekte automatisch auf die Änderung eines anderen Objekts reagieren [Eilebrecht.2019, S. 70-73]. In der entwickelten App werden Observer eingesetzt, um auf bestimmte Ereignisse innerhalb der App zu reagieren (meist auf den Klick auf den Button “Münze werfen”). Der Observer aktualisiert dann alle betroffenen reactiveValues() und führt beispielsweise die Zufallsexperimente durch. Ein Ausschnitt des Observers für die Stufe 2 wäre:
observeEvent(input$throwCoin12, {
val2$n1 = as.numeric(input$n12);
val2$amount1 = as.numeric(input$amountSeries12);
probability = as.numeric(input$probability12);
val2$vecRel = c()
for(i in 0:((val2$n1*val2$amount1)-1)){
val2$vecRel[i+1] = sum(sample(c(0,1), mod(i, val2$n1)+1,
replace = TRUE,
prob = c(1-probability,probability))==1)
/(mod(i, val2$n1)+1);
}
...
})[Pseudozufallszahlen]In der App werden zufällige Sequenzen von 0 und 1 betrachtet, welche die Ereignisse “Zahl” und “Kopf” codieren. Jedoch werden hier computererzeugte Pseudozufallszahlen verwendet. “Wenn sich diese Zahlen jedoch erst nach einer sehr großen Periode wiederholen und wenn sie „zufällig genug“ verteilt sind, so sind sie für praktische Probleme als Zufallszahlen einsetzbar.” Heute werden in der Regel sogenannte lineare Kongruenzgeneratoren zur Erzeugung von Zufallszahlen verwendet. Der erste Zufallsgenerator wurde 1946 von John von Neumann (1903–1957) erfunden. Dies geschah damals rund um die Entwicklung der Wasserstoffbombe und war somit streng geheim (Büchter und Henn 2005, 294–95).
[Performanceverlust durch sample]Die Pseudozufallszahlen werden mit der Funktion sample() (vgl. R Core Team (2019)) erzeugt. Durch den mehrfachen Aufruf der Funktion – für die Wurfzahlen \(1,2,\dots, n\) – fand ein erheblicher Performanceverlust statt. Um diesem gegenzuwirken, wird die Funktion nur mehr einfach aufgerufen, dafür aber mit mehr Elementen – \(n\) – als Rückgabewerte. Dadurch wurde die Performance wieder gesteigert. So konnte der obige Code in den performanteren folgenden Code umgewandelt werden:
val2$vecRel = c();
tmp = c();
for(i in 1:val2$amount1){
tmp = sample(c(0,1), val2$n1, replace =TRUE,
prob = c(1-probability, probability));
for(j in 1:val2$n1){
val2$vecRel[(i-1)*val2$n1+j] = sum(tmp[1:j]==1)/j;
}
}
}Anstelle von \(val2\$n1\cdot val2\$amount1\) Aufrufen von sample() wird nun die Funktion nur mehr \(val2\$amount1\)-mal aufgerufen und die Werte durch Verschieben der Array-Grenzen ermittelt.
[von plot zu plotly]Eine weitere Anpassung war das Tauschen des Plotting-Tools. In der ersten Version wurde noch die Standardfunktion plot() (vgl. R Core Team (2019)) verwendet. Diese wurde dann durch plot_ly() (vgl. Sievert (2019)) ausgetauscht, da diese mehr Metainformationen und zusätzliche Funktionalitäten bietet. Als kurzer Vergleich sind die beiden Aufrufe der Funktionen für ein Säulendiagramm angeführt:
# Plot mit barplot()
bplot = barplot(c(val0$relCoin1, val0$relCoin2),
col = c("red", "dodgerblue2"),
ylab = "relative Häufigkeit", ylim = c(0,1),
names.arg = c("Serie 1", "Serie 2"))
# Plot mit plot_ly()
plot_ly(x=~c("Serie 1", "Serie 2"), y=~c(val0$relCoin1, val0$relCoin2),
type = "bar", text = tmpStringVec, textposition = "auto",
textfont = list(color = "black"),
marker = list(color = c("red", "dodgerblue"))) %>%
layout(xaxis = list(title = ""),
yaxis = list(title = "relative Häufigkeit", range = c(0,1)))[Einfärben von Elementen]Bereits in der Modellierung der Stufen in der Entwurfsphase wurden verschiedene Sliderfarben (passend zum jeweiligen Output) beschrieben. Die Realisierung funktioniert mithilfe von CSS. Normalerweise ist eine strikte Trennung von HTML und CSS sinnvoll, da die Wartbarkeit verbessert wird. Jedoch tauchte beim Einfärben die Eigenheit auf, dass jeder style eine eigene ID (realisiert über Nummern) benötigte. Dadurch wird der style auch direkt in der ui.R beim dazugehörigen Slider definiert. Ein Beispiel zum Einfärben ist:
tags$style(HTML(".js-irs-10 .irs-single,
.js-irs-10 .irs-bar-edge,
.js-irs-10 .irs-bar {background: red; border: red}"))Damit der komplette Balken in einer Farbe erscheint, ohne einen standardmäßigen blauen Rahmen, müssen sowohl background als auch border gesetzt werden.
6.3 Validation
[Rahmenbedingungen]Durch die GUI-lastige App wurde in der Testphase ein Usability-Test an einem Bundesoberstufenrealgymnasium in Tirol durchgeführt. Dabei nahmen SchülerInnen aus den Klassen 5, 6 und 7 teil. Insgesamt ergab sich ein Umfang von 30 ProbandInnen. Der Usability-Test wurde mithilfe eines Online-Fragebogens (vgl. Fragebogen im Anhang) durchgeführt.
[Ergebnisse]Die gesamte Auswertung ist im Anhang zu finden. Jedoch sollen hier noch kurz die Ergebnisse in komprimierter Form dargestellt werden. Dabei liegt einerseits der Fokus auf der mathematischen Frage des Intros der App, als auch auf der Gesamtbewertung der App durch die SchülerInnen.
[Diagramme zuordnen]Das Intro der App soll die SchülerInnen dazu motivieren, sich mit dem Münzwurf auseinanderzusetzen. Aus diesem Grund werden zwei Diagramme dargestellt, welche den richtigen Personen zugeordnet werden müssen. Peter wirft insgesamt zwanzig Mal und Hanna zweihundert Mal. Dies wiederholen die beiden dreimal und stellen die relativen Häufigkeiten für das Ereignis “Kopf” in den Diagrammen dar (vgl. Abb. 6.3). Die Frage lautet nun: Welches Diagramm gehört vermutlich zu Peter und welches zu Hanna? Diese Frage zielt auf den sample size effect ab. Die Schülerantworten konnten in drei Kategorien eingeteilt werden:
- richtige Zuordnung bei richtiger Begründung
- richtige Zuordnung bei falscher Begründung
- falsche Zuordnung
Auffallend ist, dass 28 von 30 SchülerInnen die Diagramme richtig zuordneten. Als richtige Begründungen wurden die Stabilisierung bei größerer Wurfanzahl und die geringere Abweichung vom Erwartungswert bei häufiger Durchführung genannt. Eine exemplarische SchülerInnenantwort möchte ich nicht vorenthalten: “Das erste Diagramm (rot) ist Peter zuzuordnen, und folglich das zweite Hanna, da bei einem Münzwurf entweder Kopf oder Zahl, abgesehen des unwahrscheinlichen Falles eines Zwischenstadiums, als Ergebnis resultiert. Folglich besteht für jede der beiden Möglichkeiten eine Wahrscheinlichkeit von \(\approx 50\%\), weshalb bei einer hohen Anzahl an Würfen sich dieses Ergebnis klar herauskristallisiert (Hanna).” Bei dieser Aussage wurde sowohl das Argument eines Laplace-Experiments, als auch das Einbeziehen des Stichprobenumfangs ersichtlich. Eine nicht ganz optimale Begründung der richtigen Zuordnung war beispielsweise: “Ich habe ein gutes Gefühl dabei.” Insgesamt gab es nur zwei falsche Zuordnungen, wobei eine mit folgendem Satz begründet wurde: “Ich finde das rote Diagramm gehört der Hanna, weil die Farbe rot ist eigentlich für das Geschlecht Weiblich gedacht. Und das blaue Diagramm gehört Peter.” Eine Folgerung daraus wäre, dass geschlechtsneutralere Farben verwendet werden sollten. Jedoch bringt beispielsweise die Farbkombination Rot-Grün auch Schwierigkeiten bedingt durch die Rot-Grün-Sehschwäche mit sich.
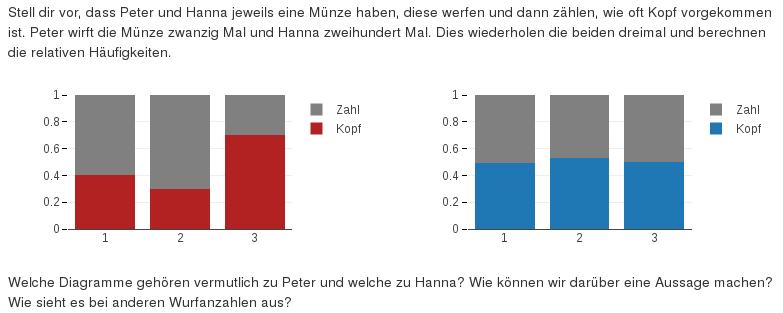
Figure 6.3: Frage nach der Diagrammzuordnung im Intro der entwickelten App
[Gesamtbewertung]Zu jeder Stufe sollten die Aspekte verständlicher Text, Bedienung, Tooltips, Aufteilung in Basis/Erweitert und Performance mithilfe der Kategorien “sehr gut”, “gut”, “es geht”, “schlecht” und “nicht beantwortbar” eingestuft werden. Sodass zu jeder vorhandenen Stufe der entwickelten App ein Feedback eingeholt werden kann. Am Ende des Fragebogens wurden diese Kriterien noch erweitert und auf die gesamte App bezogen. Somit sollen die Stufen nicht nur als Facetten betrachtet werden, sondern auch der Gesamteindruck über alle Stufen hinweg. Dadurch besteht die Möglichkeit die Kriterien in bestimmten Stufen in eine bessere Kategorie zu heben um schlussendlich auch einen besseren Gesamteindruck zu hinterlassen. Die erweiterten Kriterien, welche bei der Gesamtbewertung der App verwendet wurden, setzten sich aus folgenden zusammen: verständlicher Text, Bedienung, Tooltips, Aufteilung in Basis/Erweitert, Performance, Übersichtlichkeit, Struktur, optisches Erscheinungsbild, inhaltliche Verständlichkeit und verständliche Sprache. Diese Kriterien und deren Bewertung sind in Abb. 6.4 zu sehen. Das arithmetische Mittel schwankt sichtbar zwischen den beiden Kategorien “sehr gut” und “gut”. Die Übersichtlichkeit, das optische Erscheinungsbild und die inhaltliche Klarheit sind unter Miteinbeziehung der Standardabweichung die Kriterien, welche an die Grenze zu “es geht” kommen.
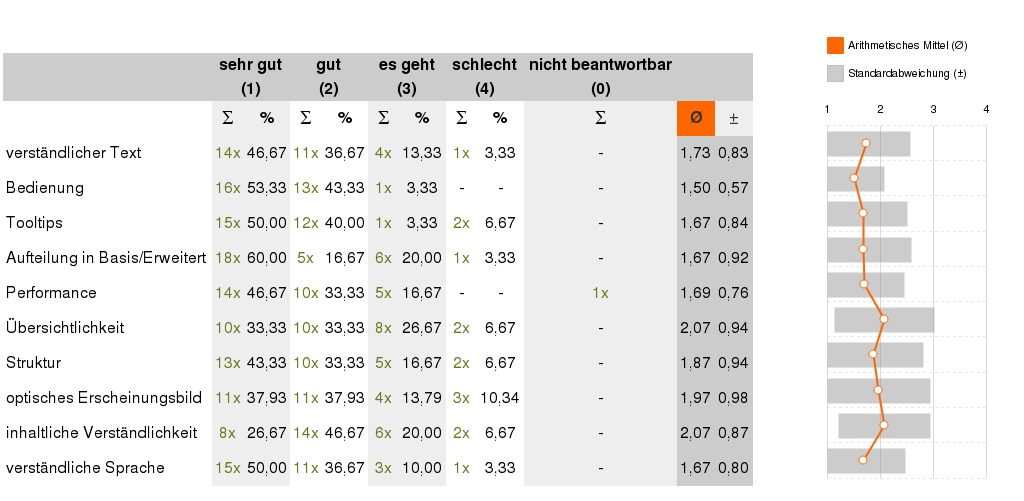
Figure 6.4: Bewertung der gesamten App durch die SchülerInnen
[Verbesserungsvorschläge]Die Verbesserungsvorschläge waren sehr vielfältig und nicht immer verständlich beschrieben. Da 30 Meinungen eingeflossen sind, kam es auch zeitweise zu Widersprüchlichkeiten. Ein Punkt war dabei die Einteilung der Einstellungen in Basis und Erweitert. Viele SchülerInnen kommentierten, dass diese Einteilung sinnvoll und übersichtlich sei, andere SchülerInnen hielten nicht viel von dieser Einteilung. Ein weiterer Punkt war die Performance: Es gab den Appell, dass die Performance bei sehr hohen Wurfanzahlen verbessert werden sollte. Außerdem wurde bemängelt, dass das Konzept der Quantile, der Binomialverteilung, etc. in der App nicht erklärt werden. Dieser Punkt ist jedoch hinfällig, da die App in bestimmten Stufen auf das bereits vorhandenes Wissen der SchülerInnen aufbaut und dieses nicht einführt. Auch in der Stufe 4 gab es unterschiedliche Meinungen. Das Spektrum reichte von viel zu kompliziert und unverständlich zu logisch und gut nachvollziehbar. Dies kann bedingt durch den Lernstand der SchülerInnen sein, da dieser in den Klassen 5, 6 und 7 doch unterschiedlich ist. Verbesserungspotential wurde auch in der optischen Gestaltung gesehen, beispielsweise wurde der Vorschlag gebracht, dass mehr Farben verwendet werden sollten.
[aufgetretene Fehler]Alle aufgetretenen Fehler sollten auch in das Feld für Verbesserungsmöglicheiten eingetragen werden. Diese Fehler werden im nächsten Abschnitt behandelt.
6.4 Evolution
[Evolution als Verbesserung]Die Evolution ist dazu gedacht, die App weiter zu entwickeln oder zusätzliche Kundenwünsche zu implementieren. Diese App betreffend werden jedoch die Verbesserungen der Fehler in die Evolutionsphase fallen. Die Fehler wurden in der Validationsphase von den SchülerInnen entdeckt, da diese beispielsweise andere Testfälle ausprobierten. Bisher bekannte Fehler sind:
- Der Plot der absoluten Abweichung funktioniert nicht für alle Stichprobenumfänge.
- Bei der Eingabe von Zahlwerten kann das Minimum unterschritten werden und falls kein Zahlwert eingegeben ist, bricht die App ab.
- Bei den Menüpunkten tauchen “leere” Punkte auf, welche nur
body {padding-top: 70px;}anzeigen.
Diese aufgetretenen Fehler und deren Lösung werden in den kommenden Abschnitten kurz umrissen.
[ERROR: absolute Abweichung]Beim Plot zu den absoluten Abweichungen funktionierten nicht alle Stichprobenumfänge. Problematisch wurde es, wenn der Stichprobenumfang herabgesetzt wurde. Beispielsweise von 300 Münzwürfen auf 150 Münzwürfe. Der Fehler entstand durch die unterschiedlichen Dimensionen der x- und y-Parameter in der Funktion plot_ly().
plot_ly(x=~1:val1$n, y=~val1$diffAbsEw, type="scatter", mode="markers",
marker = list(color = "dodgerblue2")) %>%
layout(...)Beim Verringern des Stichprobenumfangs wurde val1$n verändert. Jedoch erfuhr der Vektor val1$diffAbsEw nur eine Veränderung im Bereich [1:val1$n], behielt aber seine ursprüngliche Länge bei. Somit kam es zu diesem Dimensionsunterschied und dem Fehler (vgl. Abb. 6.5). Dieser Fehler konnte behoben werden, indem bei jedem neuen Zufallsexperiment (ausgelöst durch Klick auf den Button “Münze werfen”) der Vektor val1$diffAbsEw zuerst auf einen leeren Vektor zurückgesetzt und dann erst mit den neuen Werten befüllt wird.

Figure 6.5: Fehler beim Plot zur absoluten Abweichung
[ERROR: numeric input]Die Zahlenwerteingabe über den numericInput() warf zwei Probleme auf. Einerseits konnten Zahlenwerte unter dem angegebenen Minimum eingegeben werden und andererseits brach die App ab, sobald kein Zahlenwert im Feld stand. Dieses Problem trat erstmals beim Testen in der Schule auf, da die SchülerInnen zuerst die vorhandene Zahl aus dem Feld löschen und dann eine neue Zahl eingeben wollten. Bis zu diesem Moment trat der Fehler nicht auf, da die Zahl mit Doppelklick markiert und einfach überschrieben wurde. Das Fehlverhalten konnte mit folgendem Code gelöst werden:
observeEvent(input$nQuest, {
req(input$nQuest);
val2$nQuest = round(as.numeric(input$nQuest));
if((val2$nQuest > val2$n1) || (val2$nQuest < 1)){
updateNumericInput(session, "nQuest", value = val2$n1);
showNotification("Der Wert muss zwischen 1 und der Wurfanzahl liegen.
Der Wert wird standardmäßig auf die Wurfanzahl
zurückgesetzt.",
type = "warning");
val2$nQuest = val2$n1;
}
})Der numerische Wert wird durch den numericInput() input$nQuest an das Programm übergeben. Mithilfe der Funktion req() wird signalisiert, dass ein Wert zur Weiterverarbeitung benötigt wird. Ist kein Wert vorhanden, findet auch keine Weiterverarbeitung statt. Somit wird die App auch nicht mehr abgebrochen, wenn kein Wert im numericInput()zu finden ist. Durch die bedingte Verzweigung (if()) wird sowohl der Fall abgedeckt, dass ein Wert unter 1 und über dem Stichprobenumfang (Wurfanzahl) eingegeben wird. Ist dies der Fall, wird der numericInput() standardmäßig auf die Wurfanzahl zurückgesetzt und es erscheint eine Warnung.
[ERROR: leere Menüpunkte]Um eine bessere Übersichtlichkeit zu gewährleisten wurde mittels body {padding-top: 70px;} ein Abstand zwischen die Menüleiste und dem Inhalt der jeweiligen Stufe eingefügt. Dies führte jedoch dazu, dass ein weiterer Unterpunkt erschien, welcher nur body {padding-top: 70px;} darstellte (vgl. Abb. 6.6). Dieses Problem konnte durch das Verschieben der Formatierungsanweisung gelöst werden. Der Grund für dieses Fehlverhalten und das Funktionieren der Lösung ist nicht bekannt.

Figure 6.6: Fehler des leeren Menüpunkts
6.5 Einteilung in Interaktionsmöglichkeiten
[Klassifizierung der Variation]Wie in 4.4 Konzept der Interaktionsmöglichkeiten beschrieben, klassifizieren die sechs Interaktionsmöglichkeiten die möglichen Variationen, welche in Simulationen vorhanden sind (Wörler 2018a, 38). Da die entwickelte App auch unter den Oberbegriff Simulationen fällt, kann für diese die Möglichkeiten der Interaktion aufgezeigt werden.
[vorhandene Interaktionsmöglichkeiten]Die App erlaubt eine Variation der Anzahl der Modellelemente, da beispielsweise die Anzahl der Münzwürfe verändert werden können. Aber auch durch eine veränderbaren Anzahl an Münzwurfserien kann mit der App interagiert werden. Eine weitere Möglichkeit der Interaktion bietet das Verändern der Wahrscheinlichkeit für das Ereignis “Kopf”, dies wird mithilfe eines Sliders möglich, welcher Werte zwischen 0 und 1 zulässt. Durch diese Option der Veränderung wird eine Variation der Modellannahme erreicht. Denn anstatt eine faire Münze zu betrachten, können auch gezinkte Münzen betrachtet werden. Dies bietet auch den Vorteil die App vom Kontext des Münzwurfes zu lösen und andere dichotome Zufallsvariablen betrachten zu können. Durch die veränderbaren mittleren Bereiche (\(90\%\), \(95\%\) und \(99\%\)-Bereich) kann auch die Beziehung zwischen den Bereichen und den Münzwurfserien dargestellt werden. Somit erlauben die Quantile auch eine Variation der Beziehung zwischen Modellelementen. Die anderen drei Interaktionsmöglichkeiten kommen in der App nicht vor.
[abgeleiteter Interaktionsgrad]Laut Wörler (2018a) ist der Interaktionsgrad die Anzahl der tatsächlich implementierten Interaktionsmöglichkeiten. Wie oben beschrieben, sind folgende Interaktionsmöglichkeiten in der App vorhanden:
- Variation der Anzahl der Modellelemente
- Variation der Modellannahme
- Variation der Beziehung zwischen Modellelementen
Somit ist der Interaktionsgrad der App gleich \(3\). Bezogen auf externe Repräsentationen vereint die App noch graphische und tabellarische Elemente, wobei sowohl ikonische als auch symbolische Elemente vorkommen..
[Interaktionsgrad und externe Repräsentation]Da der Interaktionsgrad der entwickelten App bereits geklärt wurde, kann noch ein näherer Blick auf die externen Repräsentationen erfolgen. Wie in Abb. 6.7 ersichtlich ist, vereint die App enaktiv-virtuelle, ikonische und symbolische externe Repräsentationen bezogen auf den Interaktionsgrad 3. Im Bereich der enaktiv-virtuellen Repräsenationen kommen vor allem schematische Darstellungen vor. Der Vorgang des Münzwurfs wird nicht wirklichkeitsgetreu ausgeführt, sondern beispielsweise durch einen Klick auf einen Button simuliert. Auch im Bereich der ikonischen Repräsentationen sind ausschließlich schematische Darstellungen vertreten. In diesem Bereich gibt es noch eine Unterteilung in statische- und dynamische-ikonische Repräsentationen. In der entwickleten App treten statische Darstellungen im Intro auf, in welchem die mögliche Diagrammzuordnungen zu Personen im Fokus steht (vgl. Abb. 6.3). Dynamische Darstellungen sind durch alle Plots, welche direkt auf Eingaben (Veränderungen der Münzwurfanzahl, Anzahl der Serien etc.) reagieren, in der App vorhanden. Weiters sind in der Stufe 4 noch nonverbal-symbolische exteren Repräsentationen vertreten.

Figure 6.7: Interaktionsgrad und externe Repräsentation